【生成AI×設備保全 #3】設備保全AI導入の3ステップ — Zoneモデルとセキュリティ設計
EMLが提唱する「Zoneモデル」で、設備保全×生成AIの活用段階をZone1(汎用LLM)→Zone2(自社データ統合)→Zone3(業界集合知)の3段階で構造化。Zone1→Zone2が最大の価値転換点であること、Zone2以降で不可避となるセキュリティ・ガバナンス(OWASP Top 10 for LLM、IEC 62443、多層防御)の要件を整理する。

1. 設備保全×生成AIの進化を「Zoneモデル」で整理する
1-1. 設備保全×生成AI活用の進化
設備保全の現場では、ChatGPTやClaudeといった汎用LLMを報告書の下書きやマニュアル要約に活用する動きがすでに広がっている。一方で、「自社の保全データと連携させたい」「より高度な分析に使いたい」という次の段階に進もうとすると、具体的に何をどう進めればよいかが見えにくくなる。
この「汎用→ドメイン特化→業界横断」という進化は、設備保全に限った話ではない。MIT CISRが721社を対象に実施した調査では、業界を問わず企業のAI活用が4つの成熟段階を経ること、そしてStage 2(パイロット構築)からStage 3(組織的展開)への移行が業績に最も大きく影響することが明らかにされている[11]。金融・医療・法務といった他のドメインでも、汎用LLMからドメイン特化LLMへの移行が同様に進んでいる[12]。
Zoneモデルは、この業界共通の進化パターンを設備保全の文脈で整理したフレームワークである。
1-2. 設備保全×生成AI活用における3つの段階
設備保全×生成AI活用には以下のZone1~3に示す3つの段階があると考えられる。
活用フェーズ | AIが参照する知識 | 設備保全領域での具現化 |
|---|---|---|
Zone1:一般解 | 汎用LLMの学習データ(一般知識) | 文書作成補助、マニュアル要約、ヘルプBot |
Zone2:固有解 | 一般知識+自社固有データ(保全履歴・設備仕様・コスト) | 報告書自動生成、保全計画立案、コスト最適化 |
Zone3:業界集合知と最適解 | 固有データ+業界標準規格+メーカー技術文書 | 規格横断分析、中長期保全計画、What-ifシナリオ |
ここで強調すべきは2点ある。第一に、Zone1→Zone2への移行が最も大きな質的転換であること。第二に、Zone2以降ではセキュリティ・ガバナンスへの対応が前提条件となることである。

2. Zone1(一般解)── 汎用LLMの活用
2-1. Zone1の定義と位置づけ
Zone1は、ChatGPT、Claude、Geminiなどの汎用LLMをそのまま業務に適用する段階である。
ChatGPTのWebブラウザ画面等で活用するか、プロダクトには簡易的に組み込まれているものの、AIが参照するのは、直接的なプロンプトに加えてインターネット上の公開情報・書籍・論文など学習データに含まれる一般知識に限定され、自社の保全履歴や設備仕様書といった固有データは参照範囲の外にある。(プロンプトに記載すれば別だが、現実的には記載しきれない)
2-2. Zone1で実現できること
汎用LLMだけでも、設備保全の業務効率化に寄与する場面は複数存在する。例えば以下の事例は具体的なユースケースである。
- 手書きメモ・現場記録のテキスト化
GPT-4oやClaudeなどのマルチモーダルモデルは、点検時の手書きメモや写真上の注記をデジタルテキストに変換する能力を備えており、紙ベースの記録をデジタル化する入口として機能する。 - 各種文書の作成補助
日報・週報・月次報告書のドラフト作成、報告書フォーマットへの整形、文章の校正・要約といった事務作業の時間を削減し、本来の保全業務に集中するための時間を確保できる。 - 一般的なヘルプBotの構築
メーカーが公開しているマニュアルや操作手順書の内容について自然言語で質疑応答するBotを構築できる。「このバルブの推奨トルク値は?」といった、公開情報の範囲内での質問対応に適している。 - 長文マニュアルの要約
数百ページにおよぶ技術マニュアルや規格文書から、必要な箇所を自然言語で検索・抽出し、要約を生成できる。
2-3. Zone1の構造的限界
Zone1は導入しやすい反面、汎用的な回答が前提であることから、案設備保全の本質的な課題に踏み込めないという構造的限界を抱えている。
- 自社固有データへのアクセス不能
「P-001ポンプの過去5年間の故障頻度は?」「A棟の冷却塔は次回いつ点検すべきか?」といった自社データに基づく問いに対して、汎用LLMは回答を持たない。 - ハルシネーションリスク
自社固有の文脈なしに専門的な質問を投げると、もっともらしいが事実ではない回答が生成される確率が高まる。設備保全では、誤った数値に基づく判断が安全に直結するため、この問題は看過できない。 - 業務ワークフローとの非統合
汎用LLMは独立したツールであり、LLMで生成した報告書をCMMS(設備保全管理システム)に手動で転記するなど、二重作業が発生する。この手動介在が業務効率化の天井を形成する。
これらの限界を構造的に解消するのが、Zone2への移行である。
3. Zone2(固有解)── 自社データとの統合
3-1. Zone2の定義と質的転換
Zone1では、AIの参照範囲は一般公開情報に限定されていた。Zone2への移行とは、この参照範囲が自社の保全データ——設備台帳、故障履歴、点検記録、作業報告書——へ拡張される段階を指す。AIが「一般論」ではなく「自社固有の文脈」を踏まえた回答を生成できるようになる点が、Zone1との本質的な違いである。
この拡張により、たとえば「この設備の過去3年間の故障傾向は何か」「前回の点検で指摘された事項は何か」といった、自社データに基づく具体的な問いにAIが応答可能となる。汎用的な知識から固有の知識への転換——これがZone2の核心である。
3-2. Zone2で実現できること
Zone2の機能群は、設備保全業務を本館的にAIと統合したものとなる。例えば以下のような内容を具体的に実現しうる。
- 保全報告書の自動生成
点検データ、センサーログ、作業記録を統合し、報告書の下書きを自動生成する。従来、熟練技術者が数時間を要していた報告書作成が、AIによる下書き+人間によるレビューの構造に転換される。 - 類似故障の横断検索
「過去に同一設備・同一症状で発生した故障事例」を自然言語で検索可能にする。従来はベテラン技術者の記憶や紙台帳の手作業検索に依存していた知識アクセスが、AI経由で即時化される。 - 保全ワークフローの自動化
故障検知から作業指示書の生成、部品発注の起票、担当者へのアサインまでを一連のワークフローとして自動化する。人間の判断が必要なポイントには承認ステップを設けつつ、定型的な手続きをAIが代行する。 - 保全スケジュールの最適化
稼働データと故障履歴を分析し、設備ごとの最適な点検・交換タイミングを提示する。暦ベースの定期保全から、データに基づく状態基準保全(CBM)への移行を支援する。 - 自然言語によるデータ分析
「先月の故障件数をラインごとに比較して」「MTBFが低下傾向にある設備を一覧にして」といった自然言語の問いかけに対し、AIがRDB上のデータを検索・集計して回答する。Text2SQL技術により、SQL知識のない現場担当者でもデータドリブンな意思決定が可能となる。 - 保全コストの分析・最適化
設備ごとの保全コスト推移、部品調達コスト、ダウンタイムによる機会損失を統合的に分析し、投資対効果の高い保全戦略を提示する。
3-3. Zone2を実現するための技術要素
Zone1からZone2への移行は、単にデータを接続すれば済む話ではなく、以下の技術基盤の構築が必須である。
- オントロジー整備(保全用語体系の構築)
Zone2の前提条件として最も重要なのが、保全用語のオントロジー整備である。同一設備が拠点ごとに異なる名称で呼ばれる、同一故障モードが「異音」「振動過大」「ベアリング摩耗」と複数の表現で記録される——こうした表記揺れは、保全データ活用の最大の障壁となる。ISO 14224 [7] に準拠した故障モード分類体系を基盤とし、自社固有の用語マッピングを構築することが、Zone2における全ての技術要素の前提となる。 - RAG(検索拡張生成)
RAG [1] は、社内文書をベクトルデータベースに格納し、ユーザーの質問に関連する文書を検索した上で、LLMがその文書を参照しながら回答を生成する技術である。Zone2においてAIが自社データを参照する中核メカニズムとなる。 - ファインチューニング
汎用LLMを自社の保全データで追加学習させ、保全固有の用語・文脈への対応精度を向上させる。特にオントロジー整備と連動し、「ベアリング異音」「軸受け振動」「Bearing noise」が同一故障モードを指すことをモデルに学習させることで、検索精度と回答品質が向上する。 - Text2SQL(自然言語→データベースクエリ変換)
現場担当者の自然言語による問いかけを、RDB上のSQLクエリに自動変換する技術である。3-2⑤で述べた自然言語データ分析の基盤技術となる。 - 構造化JSONガバナンス
保全業務には、ベテラン技術者が暗黙のうちに把握している業務制約が数多く存在する。報告書の作成日付が実施日より過去にならないこと、定期メンテナンス周期が極端に短期に設定されないこと、点検項目に必須の確認事項が欠落しないこと等である。構造化JSONガバナンスとは、これらの暗黙知をJSON形式のバリデーションルールとして明文化し、AIの出力に対するガードレールとして機能させる仕組みを指す。AIが生成した報告書や作業指示に対し、定義済みのルールセットで自動検証を行い、業務制約に反する出力を検出・修正する。現場の暗黙知がシステム的に担保される構造となる。 - テナント分離によるデータアクセス制御
Zone2では自社の機密データをAIに参照させるため、マルチテナント環境におけるデータ分離が不可欠となる。企業ごと・拠点ごとにデータアクセス範囲を厳密に制御し、他社データとの混在を防止する設計が求められる。詳細なセキュリティ要件については第5章で論じる。
3-4. Zone1→Zone2が最大のポイントである理由
当該Zoneモデルで最も強調するのは、Zone1→Zone2への移行が、生成AI×設備保全における最大の価値転換点であるという認識である。
Zone1においてAIは「便利な補助ツール」にとどまり、設備保全の実務上の課題——「この設備をいつ修理すべきか」「限られた予算をどの設備に優先配分すべきか」——には対応できない。Zone2への移行によって初めて、AIは自社データに基づく��断支援を提供し、「業務基盤」として機能し始める。
第2回で概観したグローバルサプライヤー5社(Siemens[9]、Honeywell、IBM、SAP、ABB)が実装を進めているのも、このZone2に相当する機能群である。
なお、この「汎用→自社データ統合」という移行パターンは保全業界に固有のものではない。金融領域ではドメイン特化LLMによるセンチメント分析や不正検知が汎用モデルの精度を上回り始めており、医療領域ではRAGを活用した臨床エビデンス参照システムが診断支援に組み込まれつつある[12]。MIT CISRの調査でも、この段階を超えた企業群は業界平均を上回る財務パフォーマンスを示している[11]。Zone1→Zone2の移行は、業界を問わず生成AI活用の分水嶺となっている。
4. Zone3(業界集合知と最適解)── 業界知識の統合
4-1. Zone3の定義
Zone3は、Zone2で構築した自社データ基盤に加えて、業界標準の規格文書・メーカー技術文書を統合的に参照する段階である。API/ASME、PAS、ISOなどの国際規格、各設備メーカーの技術マニュアルまでがAIの参照範囲に含まれる。
Zone2が「自社の過去」に基づく判断であるのに対し、Zone3は「業界全体の知見」を踏まえた判断を可能にする。個社のデータだけでは得られない、業界横断的な知見を活用した意思決定支援が実現する。
4-2. Zone3で実現できること
- 規格を横断した技術検討
API 580に基づくリスクベース検査のスコアリングでP-001ポンプの腐食リスクを評価し、ISO 14224[7]の故障分類と照合してほしい」——こうした、複数の規格・データソースを横断する分析は、従来は専門コンサルタントに依頼するか、膨大な規格文書を人手で突き合わせる必要があった。Zone3対応のプロダクトでは、AIが複数規格を同時参照しながら、自社設備の文脈に即した回答を生成する。規格の専門家でなくとも、規格に準拠した判断の入口にアクセスできるようになる点が本質的な変化である。 - 複雑なシナリオ作成
Defender-Challenger法やWhat-if分析を、業界標準のパラメータとともに自動実行する。たとえば「現行ポンプを5年延命した場合と今期更新した場合のLCC比較を、API 581のリスクカーブとISO 55000のアセットマネジメント原則に基づいて評価する」といった、複数のフレームワークを組み合わせた多軸シナリオの作成が可能となる。従来、この種の分析にはアセットマネジメントの専門人材と数週間の作業期間を要していたが、Zone3ではこれらを圧倒的に短時間で実現可能。 - 中長期保全計画の作成
API 580/581[6]のリスク評価フレームワーク、ISO 55000[8]シリーズのアセットマネジメント原則、メーカー推奨スケジュールを組み合わせ、5年~10年スパンの保全計画を自動生成する。個社の故障履歴データだけでは統計的に不十分な長期予測を、業界標準の劣化モデルやメーカー推奨値で補完することで、計画の信頼性が向上する。これはZone3の最も実務的なインパクトが大きい機能の一つである。 - メーカー情報の横断統合
複数メーカーの技術文書・保守マニュアル・推奨部品情報を横断的に検索・統合し、自社の運転条件に最適な保全アクションを提示する。たとえば同一機能の設備で異なるメーカーの製品を運用している場合、メーカーごとに異なる保守要件・推奨交換周期・対応部品を一元的に比較検討できる。
4-3. Zone3を実現するための技術要素
- データ匿名化・秘密計算
Zone3の最大の技術課題は、競合企業間でのデータ共有における機密性の担保である。差分プライバシー、連合学習(Federated Learning)、秘密計算(Secure Multi-Party Computation)等の技術により、各社の生データを開示することなく、集合的な知見を抽出する仕組みが求められる。 - 業界標準オントロジー
Zone2では個社内の用語統一で足りたが、Zone3では企業間での用語体系の統一が必要となる。ISO 14224 [7] の故障モード分類を共通基盤としつつ、業界固有の拡張語彙を標準化するコンソーシアム的な取り組みが前提条件となる。 - スケーラブルなデータ基盤
数百社規模のデータを統合・検索するためのデータレイク設計、リアルタイム集計基盤、API連携アーキテクチャが必要となる。PIKE-RAG [13] が示すような、大規模産業データに特化したRAG手法の適用も検討課題である。 - ガバナンスフレームワーク
データ提供者の権利保護、利用範囲の制限、収益配分モデルの設計など、技術面だけでなく制度面の整備が不可欠となる。NIST AI RMF [5] の枠組みを参照しつつ、業界固有のガバナンス体制を構築する必要がある。
この課題は設備保全だけでなく、製造・鉱業・製薬といった他の産業領域でも共通して認識されている。Microsoft Researchが2025年に発表したPIKE-RAGは、汎用的なRAGでは産業領域の複雑な質問応答に対応しきれないことを示し、ドメイン固有の知識抽出と多段階推論を組み合わせたアーキテクチャを提案している[13]。Zone3が求める「業界集合知の統合」は、こうした技術的進展と軌を一にするものである。
さらに、テキスト・数値・画像・音声を統合処理するマルチモーダル対応も重要な技術要件となる。設備の外観画像、振動波形データ、温度トレンド、保全記録テキスト、そして規格文書中の図表やフローチャートを同時に参照・分析することで、単一モダリティでは得られない総合的な診断が可能となる。
5. Zone2以降で求められるセキュリティ・ガバナンス
5-1. Zone2でセキュリティが必要になる理由
Zone1では、汎用LLMに自社の機密データを投入しない運用が前提であり、セキュリティリスクは限定的である。マニュアル要約や文書ドラフト作成は公開情報の範囲で完結するためである。
Zone2に移行すると、この前提が変わる。自社固有の保全履歴、設備仕様、コストデータ、生産計画といった企業の機密情報がAIの処理対象に入るためである。製造業において、設備の稼働状況や故障パターンは競争上の機微情報であり、プラント安全に関わるデータの漏洩は事故リスクにもつながりうる。
したがって、Zone2以降で生成AIを業務基盤として運用するためには、セキュリティ・ガバナンスの整備が機能導入の前提条件となる。AIの高度化とセキュリティの高度化は、分離して進めるものではなく、同時並行で取り組むべき一体の課題である。
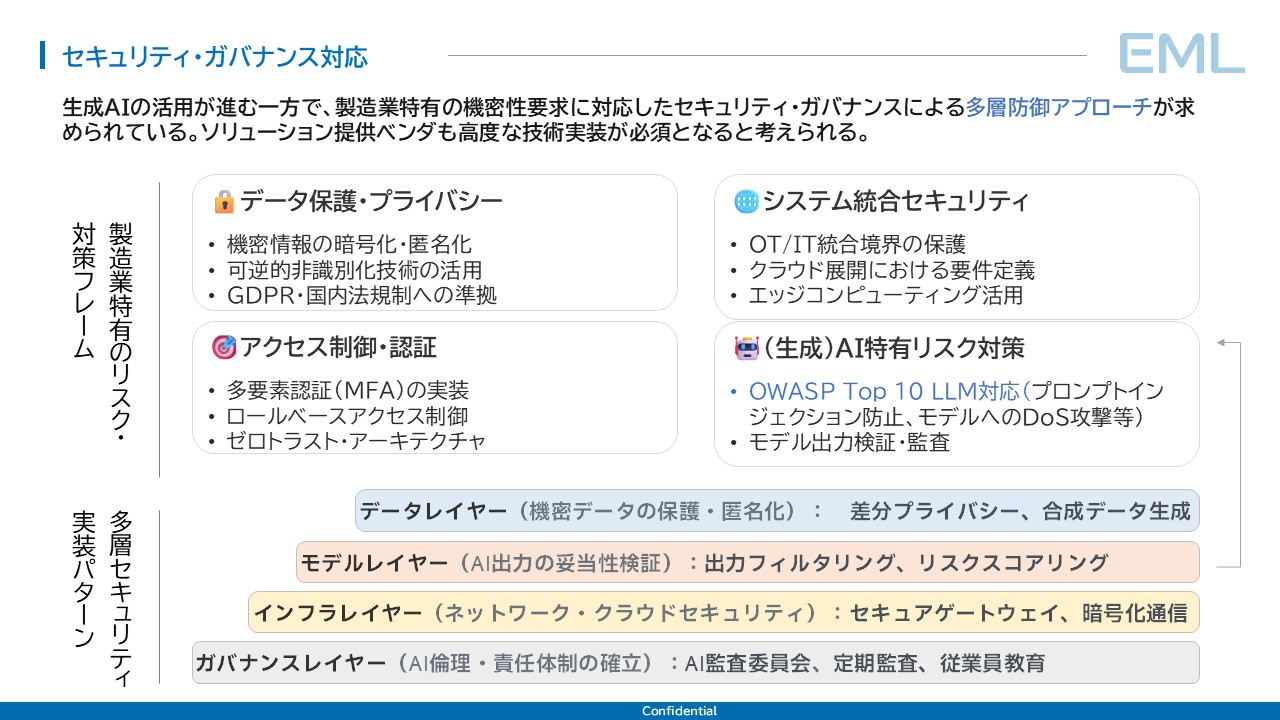
5-2. 4つのセキュリティ領域
製造業における生成AI活用では、以下の4つの領域で体系的な対策が必要となる。
領域①:データ保護・プライバシー。 設備データには、稼働データ(生産量推定の手がかりとなる)、コストデータ(設備投資計画の根拠を含む)、故障データ(安全管理に直結する)が含まれる。暗号化・匿名化の技術的対策に加え、GDPR・国内法規制への準拠が求められ、グローバル展開企業ではデータの越境移転への対応も不可欠となる。
領域②:生成AI特有のリスク対策。 OWASPが公開する「OWASP Top 10 for LLM Applications」[2]は、LLMアプリケーション固有の脆弱性を体系化したものである。代表的なリスクとして、プロンプトインジェクション(悪意ある指示によりAIに意図しない動作をさせる攻撃)、機密情報の漏洩(AIが学習データ内の機密情報を回答に含める事象)、モデルへのDoS攻撃(大量リクエストによるAIサービスの停止)が挙げられる。技術的対策と並行して、AIの出力を人間が検証する運用体制の構築が求められる。
領域③:システム統合セキュリティ。 製造業固有の課題として、OT(産業制御系)とIT(情報系)のネットワーク境界がセキュリティ上の重要ポイントとなる。制御系データをAI分析のためにIT系へ転送する際の境界保護、エッジコンピューティングによる機密データのローカル処理などが具体的な対策であり、IEC 62443(産業用制御システムのセキュリティ国際規格)[3]への準拠が基本要件となる。
領域④:アクセス制御・認証。 生成AIシステムへのアクセスは業務上の必要性に基づいて制御される必要がある。多要素認証(MFA)、ロールベースアクセス制御(RBAC:職務・役割に応じたアクセス権限の付与)、ゼロトラスト・アーキテクチャ(すべてのアクセスを都度検証する設計思想)が基本的な要件である。
5-3. 多層防御のアプローチ
上記4領域に対してEMLが推奨するのは、多層防御(Defense in Depth)の考え方である。単一の防御策に依存するのではなく、4つのレイヤーで重層的にセキュリティを確保する。
- ガバナンスレイヤー: AI監査委員会の設置、定期監査、従業員教育による組織的ガバナンス体制の構築
- インフラレイヤー: セキュアゲートウェイの配置、通信の暗号化、クラウド環境のセキュリティ設定
- モデルレイヤー: AIの出力に対するフィルタリング(不適切な回答のブロック)、リスクスコアリング(回答の信頼度評価)
- データレイヤー: 差分プライバシー(データに統計的ノイズを加えて個社特定を防ぐ技術)、合成データ生成(実データの統計特性を保持した代替データの作成)
5-4. Zoneとセキュリティ要件の対応
Zoneが上位に進むほど、扱うデータの機密性が上昇し、それに応じてセキュリティ要件も高度化する。
Zone | 扱うデータ | セキュリティ要件 |
|---|---|---|
Zone1 | 一般知識のみ | 最小限(情報漏洩リスク低) |
Zone2 | 自社固有データ | 本格的(テナント分離・暗号化・アクセス制御・OWASP LLM対応) |
Zone3 | 自社データ+業界標準+メーカー技術文書 | 最高度(多層防御・ガバナンス体制・規制対応) |
重要なのは、セキュリティ体制の整備をAI機能の導入と同時に進めることである。「まず機能を入れて、セキュリティは後から」というアプローチは、Zone2以降では通用しない。
6. EMLink Intelligence ── Zone2を実現するプラットフォーム
以上のZoneモデルを踏まえ、EMLが提供するアセットマネジメント・クラウド「EMLink」は、EMLink IntelligenceとしてZone2レベルの設備管理×生成AI統合を実装している。
EMLink Intelligenceは設計段階からAIネイティブの思想で開発されており、Zone2で求められる「自社データ参照」「業務ワークフロー統合」「セキュリティ」の3要件を一体的に提供する。
現時点での主要な機能群は以下の通りである。
- 網羅的な調査支援: 過去の保全履歴からの類似事例自動検索、同種設備の故障パターン横断分析
- 分析レポート自動作成: 月次レポート、不具合分析レポート、コスト分析レポート、リスク一覧の自動生成
- 保全計画シナリオのドラフト作成: リスク評価に基づく複数シナリオの自動生成
- 対話型の深堀機能:上記の調査・レポーティングを対話型で深堀しながら実現できる
EMLink Intelligenceの詳細は、EMLink公式サイトを参照されたい。
📚 連載:生成AI×設備保全 実践活用ガイド
- 設備保全AI活用の最前線 — 異常検知から知識統合へのパラダイムシフト
- 設備保全AIの導入事例 — グローバル5社の実装状況
- ▶ 設備保全AI導入の3ステップ — Zoneモデルとセキュリティ設計(この記事)
- 設備保全データの品質管理 — AI精度を左右するデータ基盤の実態
- 設備保全データ構造の実装 — スキーマ設計とセマンティック技術
- 設備保全AI活用の実装ロードマップ — シリーズ総括
参考文献
学術論文・技術文書
[1] Lewis, P. et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS, 2020.
https://arxiv.org/abs/2005.11401
[2] OWASP, "OWASP Top 10 for Large Language Model Applications 2025"
https://genai.owasp.org/llm-top-10/
[3] IEC 62443, "Industrial communication networks - IT security for networks and systems"
https://www.isa.org/standards-and-publications/isa-standards/isa-iec-62443-series-of-standards
[4] ISO/IEC 27001:2022, "Information security, cybersecurity and privacy protection — Information security management systems — Requirements"
https://www.iso.org/standard/82875.html
[5] NIST, "Artificial Intelligence Risk Management Framework (AI RMF 1.0)"
https://airc.nist.gov/airmf-resources/airmf/
[6] API 580, "Risk-Based Inspection," American Petroleum Institute
https://www.api.org/products-and-services/standards/important-standards-702/api-580
[7] ISO 14224, "Petroleum, petrochemical and natural gas industries — Collection and exchange of reliability and maintenance data for equipment"
https://www.iso.org/standard/64076.html
[8] ISO 55000, "Asset management — Overview, principles and terminology"
https://www.iso.org/standard/55088.html
市場調査・企業プレスリリース
[9] Siemens, "Siemens Expands Industrial Copilot with New Generative AI-Powered Maintenance Offering"
[10] EMLink公式サイト
他業界のAI活用動向
[11] Weill, P., Woerner, S. L., & Sebastian, I. M., "Building Enterprise AI Maturity," MIT CISR Research Briefing, Vol. XXIV, No. 12, 2024.
https://cisr.mit.edu/publication/2024_1201_EnterpriseAIMaturityModel_WeillWoernerSebastian
[12] Chen, Z. Z. et al., "A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law," TMLR, 2024.
https://arxiv.org/abs/2405.01769
[13] Wang, J. et al., "PIKE-RAG: sPecIalized KnowledgE and Rationale Augmented Generation," arXiv:2501.11551, 2025.
https://arxiv.org/abs/2501.11551
次回予告
第4回:生成AI時代に求められるデータ構造
- 何故ChatGPTにエクセルを投げるだけでは正しい答えがでないのか
- 生成AI時代に求められるデータ構造概論